

Background
Any software that has ever been built has had a bug or problem of some sort. Generally, these bugs might be silly things that aren’t of any major concern - like a button looking odd or only clicking when the mouse is at a certain part of it.
Some bugs, on the other hand, could have serious impact on the users of the software or those that are indirectly affected by the software - e.g. a problem with the billing system in an energy billing platform, could potentially impact the amount the customers have to pay - what if the bug resulted in final amount being multiplied by a certain arbitrary number! Imagine the reputation of the energy company who are clients of a Billing SaaS provider if such a bug were to happen.

As a software developer, you might be wondering, “why don’t you just improve your test coverage?”. That is great, in fact, it is a good starting point and preventative measure to reduce the likelihood of bugs getting to production. But no amount of testing can catch every problem in code before it gets to production. Modern software development is so complex and applications are often distributed that failure is imminent and just a characteristic of the system. Thus, failures are inevitable and must be embraced as an opportunity to learn more about the complex system and then ensure we act to prevent the problem from happening ever again.
When things go wrong in production, people are often on edge due to the urgency, the odd hour at which the incident might have happened and the potential adverse impact the incident might have to downstream components of the system. Thus, it is necessary to have a set of best practices and in reality a team to handle incidents in production efficiently.

Thus, over the last few years, tech has adopted several practices of Incident Management from other industries. In fact, incident management in tech products has gone so mainstream that there are companies making money by providing tools that streamline incident management! I don’t have to name any, you already know.
Incident Management over a decade ago - before Pagerduty

I used to work for a large financial market data provider, called FactSet. Their data updates are critical to financial companies and advisors and investment bankers and researchers. Any delays to the data update means the researchers are unable to make crucial buy/sell decisions. And if these delays happen frequently, then we lose a client. Losing a client might mean, we lose a huge chunk of our revenue. That’s how urgent incidents are in the financial world. We can’t guarantee that our users will make the right decisions, but we have to guarantee that we give them the latest and greatest data.
FactSet had and probably still has a great engineering philosophy.
Tip
If you can’t find a solution elsewhere, build it and use it.
Back in 2011, we had our paging system, we had proprietary database technologies and so on.

We all had our pager-phones provided by FactSet and if they went off, we had to acknowledge a page in less than 15 minutes before it escalated to either the senior engineers in the team or the manager.
The paging system was a simple SMS and email system that relied on the pager-phones being set up in a way that any text or email with a certain pattern of text would cause all alarms to go off on the phone.
Similarly, FactSet had its own ticketing system too, where we managed work and raised tickets. So an incident, if detected by a system, would file a ticket and then that ticket would be emailed to the engineer on call, the engineer gets the email and the pager goes off because an incident ticket followed a pattern in the subject.
The email had a link to acknowledge the page - to tell the system that an engineer is either looking into the issue or is going to look into it.
Then, based on the responding engineer’s expertise in the system, they deal with the issue on their own, or if necessary page others, especially if the engineer feels the issue is widespread because something fundamental had failed. These were the days of the data centres. We had a couple back then. We relied on a zookeeper to manage our distributed clusters, and we did have plenty of issues when Zookeeper didn’t behave.
In case of a high-impact, high-profile issue, many would have been paged and many would have viewed the incident ticket and gone through the updates posted by the engineers who were looking at the issue or were affected by it.
We only got into a call, if people had to work together to sort things out. Senior leadership who were mostly technical at FactSet understood that constantly asking engineers for updates would only delay their resolution time. Thus, all updates were posted on the original incident ticket, making the progress transparent for everyone to follow. Unless a client is making too much noise, senior Leadership never followed up aggressively.
If the incident took long to fix, like longer than 6 hours or so, the engineers on-call, who were paged earlier, relied on their teammates to swap over. This was an unsaid contract, and everyone shared the load. But in all honesty, incidents rarely get that bad - anything longer than 6 hours is generally something that would directly impact a client and hence could be very high profile and if it did get that bad, would result in a client leaving us. From what I can remember, sometimes clean-up tasks took a long time and in those cases, people handed over the remaining work and took time off.
Thus, most critical issues got fixed immediately, especially if it is within our control - not a data-center power or network problem. In case the issue is due to something that we rely on a third party for, like a network storage vendor or some sorts, that could go on for a while, but even they were sorted within 8–10 hours, the service providers were vetted really well.

That was excellent operations! And that’s because although the system was distributed, it wasn’t as distributed as today’s systems. Also, employee retention at FactSet was ridiculous! Engineers worked at FactSet for more than 10 years - the expertise and domain knowledge stayed at the company! This was phenomenal - very efficient!
Wait where is the incident commander?
In a system like FactSet, the incident commander role wasn’t officially a title. I don’t ever remember this being a title at that time. I wonder if these terms got popular after companies that provided incident management systems got popular.
However, at times when there were incidents that impacted multiple systems, one of the senior managers acted like a coordinator to ensure the right people were involved in fixing the incident. The beauty of the culture at FactSet was that everyone logged in if they realized there was a serious incident. Even if they weren’t the ones responsible for resolving the issue. It was like, management showing their engineers some moral support.
Engineers were also encouraged to page their managers if they needed help coordination cross team fixes. These managers would then take the responsibility of communicating the details in a customer friendly way to the right people.
So what exactly is an incident commander?

In modern incident management, Incident commander is one of the many roles in an incident management team, who is considered to be at the helm, piloting the team to incident mitigation and resolution. Piloting doesn’t mean they decide how to resolve the issue. They facilitate a resolution - challenging mitigation and remediation suggestions from the subject-matter experts and keeping the team focused on getting things back to normal as quickly as possible.
The incident commander is like an engineering manager of a team that’s trying to deliver something, in this case, a fix in production as soon as possible. If everyone involved is familiar with the domain that was impacted, then there may be fewer questions floating around to understand the basics of the issue. However, if everyone is not on the same page, then the first part of the incident revolves around getting a shared understanding of what isn’t working as expected and how it is impacting customers.
If many teams are involved in an incident, the incident commanders become the point of contact of the information that ties all ends together. They may not need to know every ounce of detail, but they need to know enough to let everyone know who might be best to get the details from. They are meant to see the big picture behind the incident, the customer impact, and help the team stay focussed on the issue at hand. The larger the organization and impact of the incident, the more important and challenging the role is.
What has my experience at FactSet taught me about incident management?
- Give your employees a work phone to be on-call and available outside contractual working hours and pay for data - some countries charge extortionate amounts for data
- The priority is always to mitigate/minimize impact to clients as soon as possible, especially if resolution is going to take longer, which can be the case many times
- Get the right people involved in incident analysis and mitigation as early as possible, this will help speed up the recovery of the system and also set the right severity
- Keep relevant stakeholders informed throughout the incident management process - using whatever ticketing system you use
- Although finding the root causes and creating permanent patches for fixing the causes may be high priority over other work, this may take a long time depending on how difficult the fix is. Thus, prioritize service recovery before anything else
- Incident commanders are, first and foremost, coordinators and facilitators of getting the subject-matter experts to work towards immediate mitigation and resolution. They aren’t the ones resolving the issue
- A good incident response process is crucial in ensuring we don’t violate any contractual obligations to our clients
Complexity contributes to need for processes
When I look back, what I remember is that FactSet never really had the process codified as an incident response process then. It all just grew organically. We had subject-matter experts everywhere. That was just how FactSet rolled. And things were in our little data centres somewhere in the USA. The culture of engineering was all about nurturing and retaining talent. People worked there for several years! Excellent career paths for progression, similarly good perks if you do well.
Fast-forward a decade, and now I work at Kaluza, an energy billing SaaS company that is a spin-off of Ovo Energy.
Here, we have systems that were born as microservices were getting popularized. The teams were structured for velocity, with very little coupling in between. Every team had their own tech stack and services, and also the people and skill-set required to build and maintain everything. However, over time, people moved and teams have changed, and we all know how it is to inherit something that one didn’t build. The complexity of the entire microservices ecosystem can be daunting, even with good observability. Because if you were to go by the logic of 2 pizza teams maintaining a handful of microservices, it is plenty of microservices for about 200ish engineers! But that is now the norm in most tech companies.
However, at Kaluza, we are a very adaptive organization, continuously investing in improving what we do and how we do it. Thus, over the years, we have invested in various initiatives that have improved platform wide observability, from integrating a world-class application performance monitoring service, adopting standard structured logging practices to integrating DORA metrics into our pipelines. As we have grown, to manage change better, we have adopted several of Information Technology Infrastructure Library (ITIL) practices.
Software development is a sociotechnical venture and hence it is complex and these are to be expected.
This also meant that we needed a good/great process for incident management to ensure that we could resolve or mitigate client impact as quickly as possible in case of an incident.
Thanks to the great work of our Service Management and Reliability Operations teams, we now have a process that works.
Where do we start?
We all know that incident response is just the starting point to handle an incident. There is a lot that happens after that. And this whole thing is what we call Incident Management.
Create a contact directory
What’s best to do is to create an index of systems and map them to the people responsible for those systems and a way to contact those people. This is crucial so that if something seems unfamiliar during the time of an incident and someone suspects that Team X might be able to help, then we must get someone from Team X on the incident call as soon as possible to confirm what might need to happen.
Create a guide on how to categorize an incident
Incidents have to be declared to be of a certain severity and priority. Most modern systems just assign one or the other. This might also be down to the incident management software that you use, whether you assign an incident a priority or severity.
This helps the service desk, to determine if something requires paging a team in the middle of the night or could wait until the subsequent day. Similarly, helps engineers to declare incidents if they are paged by failures in their systems by good monitoring and alerting.
This is crucial because paging someone is expensive. You are interrupting someone’s time-off, or sleep, or whatever human beings do outside of work. This will impact how they can perform the subsequent day. Thus, these guidelines to determine the severity of incidents help the ones attempting to create an incident decide if the urgency warrants paging someone.
Define guidelines on dealing with major incidents
It is good to have some high-level steps written down for everyone to refer to in case they were to determine an incident as a Major Incident. This is a run book for when one is paged so that one can deal with it as quickly as possible without having to think too much. This is especially useful if it happens in the middle of the night while most people are half asleep when woken up.
At Kaluza we follow guidelines on what to do in the first 30 minutes of an incident, which is extremely useful. To give you an idea of what we do:
- Get the team together and start a video call
- Understand the situation - what do we know is unexpected, what has been done so far, is there a likely point of failure?
- Create an incident statement - define the known impact and symptom
- Assign explicit roles and announce the roles, so everyone’s on the same page
- Incident commander
- Deputy - communication lead
- Subject-Matter Experts - the engineers, tech leads, product, etc.
- Communicate early and often
- Stabilize the situation appropriately
- Plan and announce the time-boxed set of next steps and schedule call after that time-box to re-assess the situation
In fact, the series of steps that I have stated above forms what we call the Incident Management Loop, which, I think, might have been popularized by PagerDuty. They are as follows and to be repeated until the incident is resolved:
- Assess
- Stabilize
- Update
- Verify
Automation is your friend

Make use of automations where possible to simplify and expedite the process. Some ways you can improve your incident management process through automation are:
- Creating an incident on your incident management software could publish/announce this event to a certain communication channel. E.g. if you use Slack, a channel that everyone is subscribed to
- Automations could create a temporary incident specific channel and add the person who raised the incident automatically to the channel on slack or Teams or whatever other communication tool you use
- You could also have an automation to create a link to a virtual room that those interested or involved can join and drop off as they become available. Although, any interference might need approval from the Incident Commander.
- Creating an incident should automatically page the incident commander on call - making the whole process easier to handle
Roles and Responsibilities
To begin with, you only need a couple of roles.
- Incident commander
- Deputy - communication lead
- Subject-Matter Experts - the engineers, tech leads, product, etc.
However, I know there are companies that have the money and process maturity to have many more roles. E.g. Google has plenty of specialized roles like below:
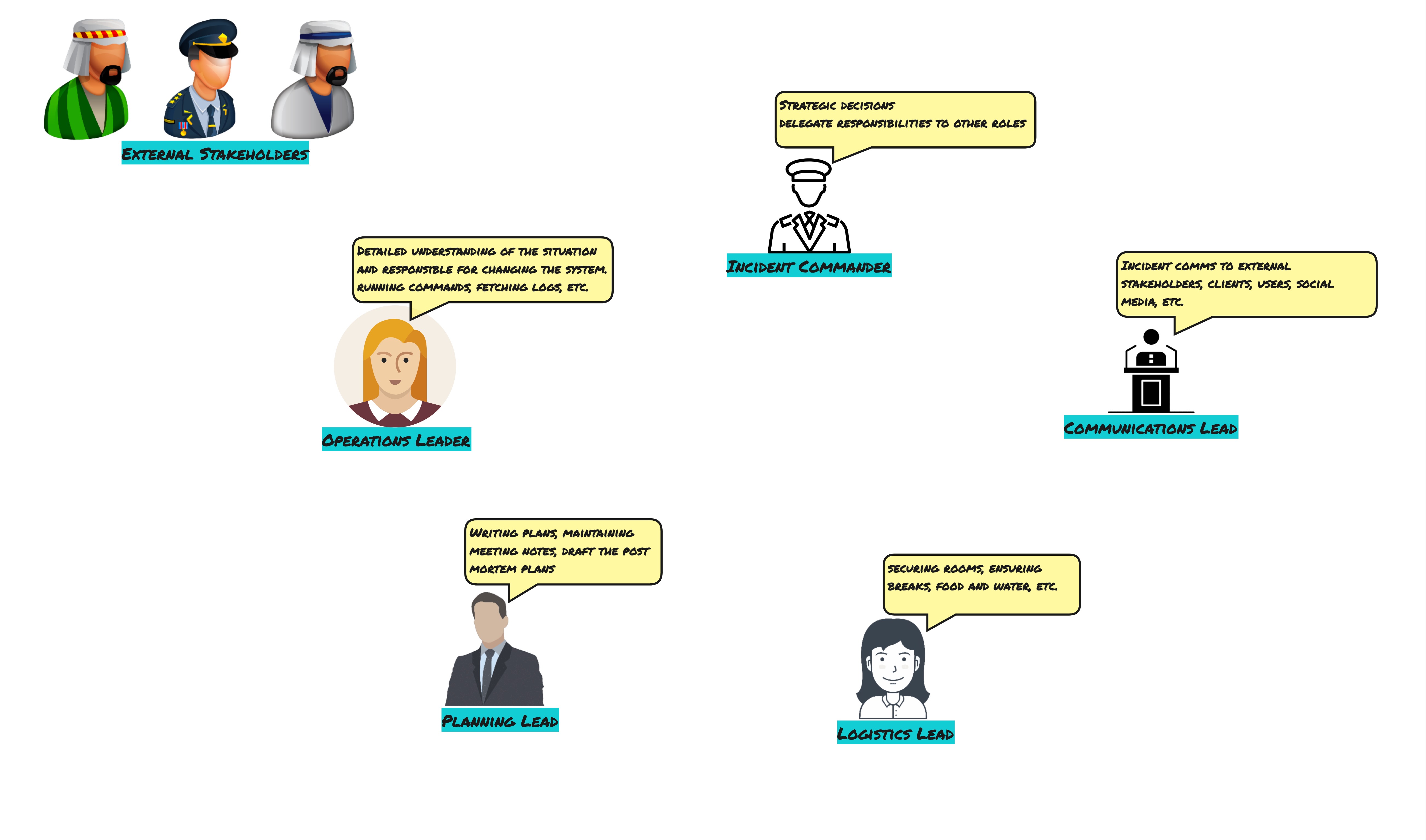
The various incident management roles at Google - open image in new tab/window to view larger image
Not every company has to have that many roles. And not everyone operates at Google’s scale. So it doesn’t matter if you only have two roles, so long as you keep the incident commander separate from the role of the subject-matter expert(s). The point being, it gives the person working on resolving the incident, the focus they need to do it properly, instead of having to coordinate the various people involved.
Blameless postmortems

Post-mortem sounds really depressing. So your company may call it a Retrospective instead. I don’t really care much about the name. We all know something bad happened - an incident, and we are trying to learn from it. No need to get too emotional about it.
What you must understand is that this process of looking at what just happened and learning from it is not to find a scapegoat to put the blame on. This reflection is to see how we can:
- Prevent the same incident from happening again
- How we could have responded better if at all
These are the two main things to focus on. If you think a human action resulted in the incident, then find out what in the system allowed that person to do such a thing and fix the system and not fire the person.
Many people look at postmortems and obsess over the root-cause. These days, everything is built on the cloud that relies on various services that are distributed around the globe that incidents often happen as a result of several causes.
I have had very long discussions on what a root-cause is, and it almost seems that there is some stigma around something becoming a root-cause. It is not something to blame. Whenever I have to explain this, I use Google SRE book’s definition of a root cause.
Info
Root Cause
A defect in a software or human system that, if repaired, instils confidence that this event won’t happen again in the same way. A given incident might have multiple root causes: for example, perhaps it was caused by a combination of insufficient process automation, software that crashed on bogus input and insufficient testing of the script used to generate the configuration. Each of these factors might stand alone as a root cause, and each should be repaired.
Healthy on-call rota

I cannot stress the importance of taking some time-off of work regularly. This must also be the case when it comes to being on-call out of hours. You really don’t want someone to be working and be on-call throughout their tenure at your organization. Everyone needs some downtime.
Systems must be maintained by teams, and the burden of maintaining the system or being first responders must be shared among team members. Thus, ensure that you have the sufficient number of people in your team or in your rota.
I have seen situations where teams are too small to have a healthy rota. Thus, a group of teams who share a similar tech stack share the on-call rota. It is a bit of a leap of faith. But over time, the people on call tend to develop excellent run books and automations and sometimes even re-architect systems to ensure that incidents aren’t repeated, thereby improving the overall stability and reliability of the system.
Guidelines to ensure your rota is healthy
- At least 4 members are in the rota, so everyone gets at least 3 weeks of rest from out of hours on-call. More would be better, but you know you have to start somewhere
- Members have been trained and are comfortable to deal with the incident themselves without having to page others
- There is an escalation policy that ensures someone other than the person on-call would get notified in case the designated person cannot respond on time
- Ideally, a primary and secondary on-call would be great. This adds a level of redundancy, especially in long-running incidents or for onboarding newer members to the rota.
- If your on-call onboarding includes shadowing and reverse-shadowing, you are doing very well!
Compensation for out of hours inconvenience

An important part of all this is the compensation for going on-call outside working hours. This is something I have noticed to be very different from company to company. I have heard that in American companies, being on-call isn’t paid an additional amount.
This is not the norm. I remember FactSet didn’t pay us a penny for the movies or parties that we had to leave, or even the sleep that we lost. FactSet’s policy was that - going on-call was part of your job, and we may need you to be able to operate outside working hours if needed. I have read online on some patterns of how this is done, and I have experienced some myself.
At Kaluza we understand that our employees are not slaves, and we respect people’s personal lives. Going on-call means, that you have to remain on stand-by and have a good internet connection. When Kaluza implemented on-call, we conducted an extensive survey of how people felt about being on-call and listened to their concerns. We tackled many of the issues that came out of it. It was interesting for me as I had been at a place where going on-call was not a matter of choice but rather an obscure part of the employment contract that people often overlooked until they were asked to go on-call. So during these sessions, I felt like my co-workers were so lucky that their employer cared so much!
Thus, at Kaluza, employees are compensated for being on-call. The compensation is based on the geographical location of the employee and the employment laws prevalent in those countries. Thus, we opted for a flat rate - weekdays have a rate and weekends have a higher rate in the UK and Europe, however, in Europe, if one were to get paged, they get compensated an additional amount per hour for dealing with the resolution of the incident.
I have also heard of some companies giving employees flat rate compensation and if they were paged, especially during public holidays, they get additionally compensated with time off in lieu.
Summary
I didn’t think this post would end up being this long. I think I have rambled a lot. These are just my thoughts on how to get a good incident management process going in your organization.
Maybe some other time I’ll share how I ran some mock incident sessions - table-top incident role play - incident response dry-run, whatever you call them. I did these to improve the confidence of my engineers to be on-call outside working hours and to get them familiar with the steps involved.
I’ll leave you with my favourite incident management related quote
Tip
Never make the same mistake ever again