

What is SRE?
SRE stands for Site Reliability Engineering.
That’s just a lot of words.
What does it mean though?
Site Reliability engineering is what IT operations would be if it was run by software engineers.
That’s an interesting take. But it was not helpful in clarifying anything about SRE just yet.
Let’s try probing more.
How did we go from Development to SRE?
You know the part where people deploy software and then ensure things run fine in production.
Those teams that are responsible for ensuring production systems are stable and if there are any issues, are probably the first responders to help triage if it is an operational issue or a programming logic issue.
This part is generally the responsibility of an Operations team. Now if you work in a relatively new company, maybe things are different.
For those who didn’t follow: Why? You ask.
The advent of DevOps
I bet by now everyone has received one of those emails from a recruiter looking for a DevOps engineer. You might have had your own moment of but DevOps is not a role, it is a culture, a union of people, processes and tech.
Yes, you are right. But try explaining that to someone who has not understood it.
DevOps is a portmanteau of Development and Operations.
Ooo! you say, “Thank you Captain Obvious”.

Well, I had to start somewhere to take it further.

Once upon a time
Software development was painful. For some it is still painful.
There used to be development teams, testing teams and finally the operations team or the application production support team. There were so many different teams like this. Sounds like a party already! Not a fun one though.

The development would build something, and chuck that deliverable over a metaphorical wall to the software testing team. It is almost like the dev team saying “Our job here is done. You see if you can break that now.”. The testing team would reply with “see you soon then” with confidence and almost a devilish smile. They knew it would not be too long before they filed a bug with what was delivered - handed over to them from the dev team for testing. If a bug was found, things would be chucked back to the dev team for re-work.

Once the test team had done their job of ensuring the deliverable was fit for purpose, they would chuck it over another metaphorical wall to the app support/operations team, who would then be responsible for deploying things to production and ensure it was running fine. If they ran into issues deploying, they would have to seek help from the development team. Fun part, they might be in a completely different time zone from the dev team. Releasing something could take a while, waiting for someone to respond and then figure out what exactly was wrong.
This sort of a structure for an organization often led to a lovely blame culture.
Some statements overheard during this time:
“It was the development team’s fault. They couldn’t develop something that would run in production”
said the production support team.
“It was the design document that was ambiguous. We didn’t have a choice but to make assumptions”
said the development team.
“The dev team, didn’t account for this use-case, which is something a user not familiar with the system would have done”
said the test team.
“That is not a bug. It is a feature. That is how the system is supposed to work. You are testing it wrong.”
said the dev team to the test team.
“I followed the steps in the release notes. But now I get this error.”
said the production support engineer to the developer who responded to a page at 2am her local time.
See the problem yet? So much fun! Such a blame party!

Silos are not for developing software
In the earlier scenario, you can see how the development team does not know how things are deployed to production. They have no way of testing the deployment process. They just hope if it works on our environment, it will work in production. And blindly continue with further development and passing on their deliverables to the test team.

The development team, works on their software based on a design document that was handed to them by the business analysis team or solution designers or whatever the fancy name you have or had in your organization. They rarely get to even meet the designer in person. Everyone was in the assembly line of the waterfall development life-cycle. One cannot afford to be slow as their team would be openly called out! You had to save face!

Some companies used to claim that they were agile and still follow this practice that I just shared. Anyone who really understands the agile manifesto, knows that this is not agile. Just because you create a deliverable every two weeks, does not mean it is agile. I will let you go read about agile later.
So this type of development life cycle, where one team chucks things over a wall to another, is unhealthy for the reasons we mentioned earlier. The developers don’t share or take ownership of anything beyond unit testing. They just want their code out of their sight. This lack of ownership means, you get application that might either be of poor quality or would not scale or simply poorly tested.
How do we solve this mess?
Let’s ask why aren’t development teams able to be responsible for all things from end to end? Why are development teams not working closely with operations teams?
You made it, so you own it
The essence of DevOps is to avoid such silos and create an environment where the team(s) responsible for developing the feature has ownership of the entire life-cycle from design to development to test to deployment and maintenance!
That might be a lot of responsibilities for a team and building such a team can be hard as quite often, operations members need a different specialised skillset compared to the developers.
So it doesn’t necessarily have to be like one person in the team is solely responsible for operations. It just has to be a culture where there is transparent collaboration between the development team and operations team, through whatever method is most suited for the organisation. Maybe there are operations ambassadors who are embedded in development teams, who regularly attend the development team standups or feature discussion meetings to provide their input in how to productionise the feature.
This way the team knows what they designed, they know what they coded and hence what would work and what has to be tested and also where and how it should and could be deployed and what would need to be done if they had to scale! Because when the feature was being built, development team worked closely with the operations team!

Although the name suggests only a merger between development and operations, the development part includes creation of an application that is well tested and is fit for purpose and implicitly also includes Security. Recently this has also been known as DevSecOps. The operations part comprises of frequent deployment to production and maintaining a fault tolerant application.
In other words:
- Development team is responsible for pushing new feature changes.
- The same team or set of people across couple of teams are responsible for ensuring stability and reliability.
- Where it is DevSecOps, there is often the security aspect considered in the same team or the group of people
Bringing them together makes sure that there is a balance between the frequency of new features going out and work related to stability and reliability.
So DevOps and Agile are?
DevOps is a movement to break organisational boundaries and enable collaboration between development team and the operations team and quite often a security team, where security team members are not part of the operations. It touches every aspect of the software development lifecycle. Just like people say Agile software development, DevOps culture is all about collaboration, automation and creating a shared sense of responsibilities among the right group of people who may or may not be in the same team in the org-chart.
The fact is that in order to be truly agile, you need to have a DevOps culture.
If you read the principles in the Agile Manifesto, you will realise that it all boils down to some core elements:

Similarly, for DevOps, I am going to borrow what I learned from The Phoenix Project, where the authors call it the three ways:
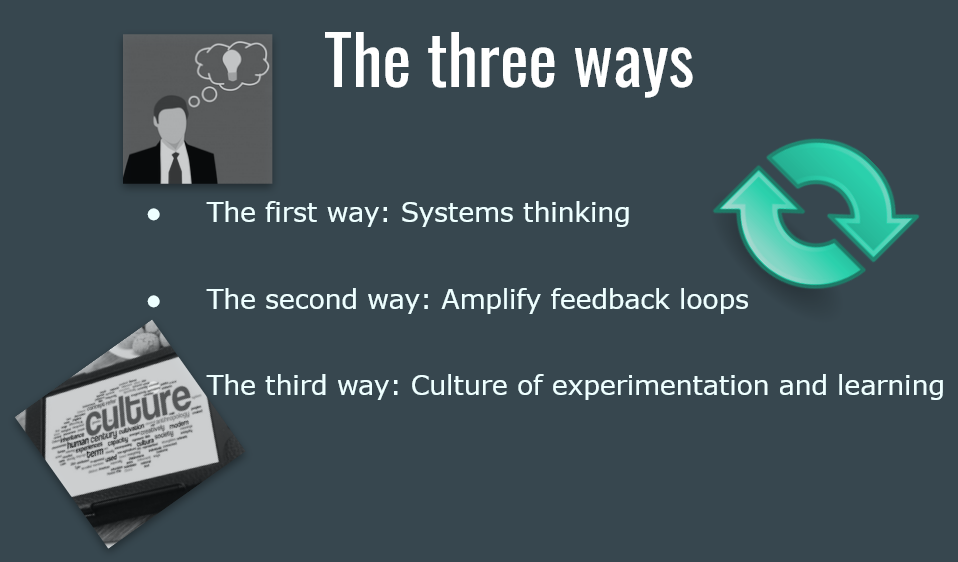
In the end the outcome is similar: the ability to create an environment where new features can be released quickly and production systems stay reliable. DevOps enables agility.
So why did SRE become a thing?
Back in 2000s, Google started SRE.
They formed a team whose sole responsibility was to build and maintain reliable systems. They had a huge responsibility to ensure that Google’s key services were never down.

Fun fact, SRE had nothing to do with the original DevOps movement. It was purely born out of Google, some practices they formed to ensure reliability of production applications. But co-incidentally it ended up solving most of the problems that DevOps was trying to solve!
How does SRE solve organisational silos?
SRE being a team responsible for maintaining reliable systems, shared ownership with developers of the same set of tooling across the whole organisation for maintaining production systems. Where there is shared ownership, there could be friction but at the same there will be collaboration.
With the developers and SREs contributing to such tooling, we get to have a really good tools to get things done fast that caters to both developer and production engineering viewpoints! Great stuff!
Shit happens! It is okay
This something that as a developer you might not be happy to accept. For SREs failure is just another Tuesday. For developers, it may not be. This outlook towards failure among SREs, means they are better prepared to deal with failures and introducing resiliency in systems. Ideally developers working on distributed systems must design for failure. But this doesn’t happen often enough.
SREs ensure that developers think of failures through something called SLOs, Service Level Objectives.

This is basically a contract that states an acceptable failure rate based on whatever industry or sector your application is in. A simple example: what level of availability do you want your application to be? SREs will hold developers accountable to this.
And because failure is treated as normal, SREs champion blameless postmortems. The reports from the postmortems are then gathered and catalogued and some analytics can be done to identify trends about failures.
Release small changes frequently
If your organisation is considering SRE, then you probably already have a good continuous integration system in place and your developers already integrate small changes into their respective main branches that gets automatically tested in several different environments, before getting deployed to production. Or if the org is only just starting up, then maybe you are building that system at the same time.
This is fundamental when maintaining a reliable system. The smaller the changes that go to production, the easier it is to roll it back in case it introduces a horrible bug. Larger changes, could lead to several inexplicable dependencies that are hard to undo. So this is something actively encouraged whether it is a DevOps culture org or SRE.
Tooling and Automation
This cannot be stressed enough. Achieve Zero Toil is an important goal of SRE. The focus is on brining long term value to the system and not short term gains. That is, when a problem occurs, build an automated way to prevent that from happening ever again or an automated mechanism to mitigate impact on failure. Toil is anything mundane that doesn’t bring long term value but has to be done repeatedly. If you don’t like repeating the same things over and over, you’ll love this part. Automate everything.
Measure everything

That which cannot be measured, cannot be improved
I don’t remember exactly who said that, but it is true. In order to see the improvements from your investment in SRE or DevOps or any practice that promised improvements, you must measure it. The same applies here.
DevOps and SRE

As you can see from the earlier points, SRE pretty much achieves all the things that DevOps cares about. Maybe even does more. I really cannot draw a line here. But it is kind of a concrete implementation of the principles made popular by DevOps.
What about those acronyms you mentioned earlier?
SREs focus on some special acronyms, just like the name.
SLI - Service Level Indicator
These are point in time metrics about a system. They are key in creating an SLO. In the simplest terms, SLI answers Yes or No to the question of Is your system healthy? at any given moment.
Some popular examples:
- Latency
- Availability
- Error Rate
- Throughput
This is specific to a system and depending on the type of system you are building, you might put your emphasis on a particular metric. A good SLI generally has a loose correlation with the happiness of your end-users. So if your customers are developers, then developer satisfaction improves if your metrics improve.
Generally those involved in determining this indicator are developers, SREs and product team members.
SLO - Service Level Objective
This is a binding target for a collection of the SLIs. This is target over a period of time. Periods can vary based on your industry, sector, application type, etc. Could be monthly, quarterly, yearly etc.
Objectives are generally agreed upon by the SRE and Product teams.
SLA - Service Level Agreement
This is a business agreement with a customer of your application/service. Failing to meeting the terms of the agreement, could cost your company dearly. And ensuring that your SLOs are good enough to avoid a breach of SLA is important. So generally companies ensure that SLO breaches are tighter than what’s stated in the SLAs.
Usually deal between Sales team and customers.
How does this improve reliability?
We have most commonly seen availability mentioned as 99.999% or the likes and never 100%. This is because it is almost impossibly hard to build something like that. Thus there is a margin of error that SREs call the Error budget.
Error Budget
The simplest way to describe this is to say: An amount of failure you can tolerate without a problem.
Let us try to explain how that relates to real life. The moment the system starts to deplete the error budget, i.e, as the system starts breaching its SLOs, it is an indicator that the team has to invest efforts in improving reliability and stop focusing on releasing features. What better way to take care of your technical debt.
It might be helpful to look at an example.
Let us say your application uses request latency as a metric and you have decided that your request latency should be at most 200ms. You ensure that your system logs this for every request and you build data over time for this. A cumulative version of this can be used as an answer to the question of Is it good or not?.
An error budgeting graph could then be plotted based on how long has the system been good or bad. The longer the system remains good, the more the error budget, the longer it has been bad, the lesser we have in our error budget. Thus by looking at what’s remaining in the error budget, we must prioritise work towards improving reliability vs building new features.
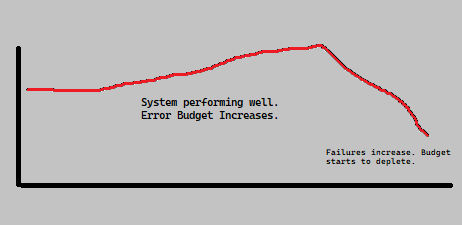
This is a delicate balance.
As SRE teams are separate from the development team, if developers or product choose to not prioritise improving reliability when the error budget is almost depleted, the SRE team would choose to discontinue their partnership and hand over the maintenance of the production systems’ responsibility to the developers. This however, is an imaginary scenario and I assume that developers are mindful of why it is important to invest in reliability improvements when the error budget depletes.
Summary
SRE and DevOps are different. DevOps is a set of principles that attempts to improve collaboration between development teams and operations to achieve agility. SRE can be described as a prescribed way of achieving what DevOps philosophy desires. Some even use the analogy of if SRE was a class, it is one that implements the DevOps interface.
A partnership between Development teams, product and SRE teams is essential in achieving an organisation wide common tooling that improves efficiency. It is also essential to pick the right type of metrics to monitor that ensures a highly available and reliable production system. This then helps strike the balance between investing efforts in improving reliability vs feature delivery.