
Background
I have in the past, in my previous job, used ElasticSearch extensively for our internal search.
When I joined my current firm, I proposed using Elastic Search for our policy search problem, which apparently was slow and inefficient. This wasn’t surprising at all to me, as they were using simple SQL to search for relevant data. This was bound to be slow.
So having proposed Elastic Search, I did a little POC and showed how easy it was for me to set up Elastic search on my machine on one node and showed how searching was a breeze using RESTAPIs and other clients. This POC was sufficient enough for us to consider a wider project and develop a solution which later got ported to Azure Search as we migrated to the cloud. To this day, we haven’t regretted our decision.
What is Azure Cognitive Search (formerly Azure Search) ?
Azure Cognitive Search or formerly known as Azure Search is Microsoft’s Search as a Service on Azure platform that provides APIs, Infrastructure, tools for building a high performance search solutions for web and mobile applications.
What is a Search engine for your application?
Search is an essential feature for any application. Whether you have a large e-commerce store selling products or whether you are a content creator, creating podcasts and articles, your customer or subscribers would want to quickly refer to something they have seen or read in the past or might want to find out if you had what they were looking for.
You cannot always forward complex textual queries to a SQL database and rely on SQL’s string search using LIKE to make your search work. That is just sub-par and will quickly become a pain point for your application.
Unique features of a search engine
Search engines, are generally NoSQL database management systems, dedicated to searching for data. Some of the unique features of such an application are:
- Support for complex search expressions
- full text search
- stemming or tokenization (Read more here: https://docs.marklogic.com/guide/search-dev/stemming)
- ranking or grouping search results
- Geospatial search (https://docs.marklogic.com/guide/search-dev/geospatial)
- Distributed search features
Popular search engines
- Elastic search
- Sphinx
- MarkLogic
- Splunk
- Solr
Why Azure Cognitive Search and what do you get with ACS?
I have already listed several popular search services there. But why Azure Search then? Well, if you already have your applications on Azure, Azure search just makes it easier to integrate things together. Having all the tech is great but what good would it do if you had to spend ages trying to integrate them? That’s the selling point here. However, there might be applications you have already been using and you just need to move them to Azure, in that case, you may not need to jump onto Azure Search.
Azure Cognitive Search features
As you would expect from any search service:
- Indexing capability - full text search with storage for your content
- Text analysis and some AI enrichment if necessary
- Extensive query capabilities, Lucene syntax and type-ahead
- REST based API and client libraries for multiple languages
- Integration with other Azure services - machine learning, data services etc.
Where does Azure Search live in my application architecture?
Search service is suppose dto sit between your external data stores and your client application. The client sends queries to a search index and handles the responses.

Azure Cognitive Search in your application architecture
What is Azure Cognitive search made of? Key Concepts?
When working with a Search database, you will encounter some terms which make up the fundamentals of the search database.
- Index - analogous to a database. This is the searchable data that you have in your search database. You create a searchable service by first creating an index. In order to create an index, you need a schema.
- Schema - analogous to a table. This is generally supplied in JSON format. Just as how a relational database would have a schema to define the structure of the database, a search index has its structure defined in a schema. The schema describes the fields this index can contain, each of which has a certain number of attributes. Pasted an example from the docs here:Most of the fields in the list of the schema fields are self explanatory. However, some might seem a bit vague. So I’ll try and describe those here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29{ "name": "name_of_index, unique across the service", "fields": [ { "name": "name_of_field", "type": "Edm.String | Collection(Edm.String) | Edm.Int32 | Edm.Int64 | Edm.Double | Edm.Boolean | Edm.DateTimeOffset | Edm.GeographyPoint", "searchable": true (default where applicable) | false (only Edm.String and Collection(Edm.String) fields can be searchable), "filterable": true (default) | false, "sortable": true (default where applicable) | false (Collection(Edm.String) fields cannot be sortable), "facetable": true (default where applicable) | false (Edm.GeographyPoint fields cannot be facetable), "key": true | false (default, only Edm.String fields can be keys), "retrievable": true (default) | false, "analyzer": "name_of_analyzer_for_search_and_indexing", (only if 'searchAnalyzer' and 'indexAnalyzer' are not set) "searchAnalyzer": "name_of_search_analyzer", (only if 'indexAnalyzer' is set and 'analyzer' is not set) "indexAnalyzer": "name_of_indexing_analyzer", (only if 'searchAnalyzer' is set and 'analyzer' is not set) "synonymMaps": [ "name_of_synonym_map" ] (optional, only one synonym map per field is currently supported) } ], "suggesters": [ ], "scoringProfiles": [ ], "analyzers":(optional)[ ... ], "charFilters":(optional)[ ... ], "tokenizers":(optional)[ ... ], "tokenFilters":(optional)[ ... ], "defaultScoringProfile": (optional) "...", "corsOptions": (optional) { }, "encryptionKey":(optional){ } } }- searchable - participates in the full text search - only applicable to textual data
- suggester - going to be available for type-ahead like use
- facetable: that is read as
facet-able. Notface-table. - an attribute that could be a category with their numbers. A subgrouping. Most often seen in e-commerce land where every brand would havexitems of the type you searched for.
- Documents - analogous to rows in a table
- Indexing - a process like an extract, transform and load that gets the data into your search service.
- Indexer - analogous to a web crawler - keeps indexes fresh with latest searchable content. Changes to your operational data can trigger the indexer to update the index.
A lot of these concepts can be found in the docs, spread across several parts of it.
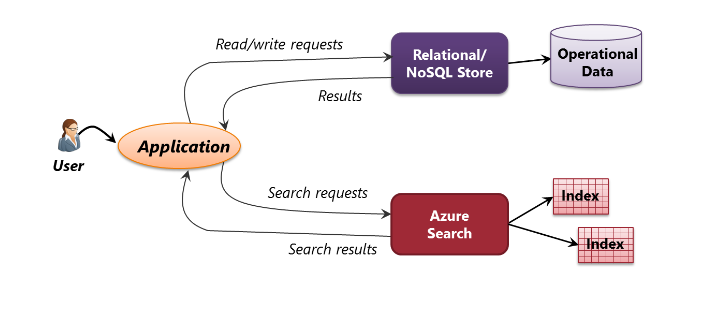
Azure search helps developers create applications that can search their operational data
Create a search service
When creating a search service, you’ll encounter some new concepts. You have a large dataset, so it would be wise to understand how it will grow and estimate what capacity you’ll need to support a searchable index for your data and also manage expectations regarding the workload.
Capacity is based on replicas and partitions.
- Replica - copy of the search engine
- Partition - units of storage
You can choose to scale up each resource independently to deal with your workload. Bear in mind that there is a cost associated to it.
Tweaking capacity is not an instantaneous change - according to the docs it might take up to an hour
Read all about this in the planning capacity section. This is important stuff and is crucial to know how much your search is going to cost you.
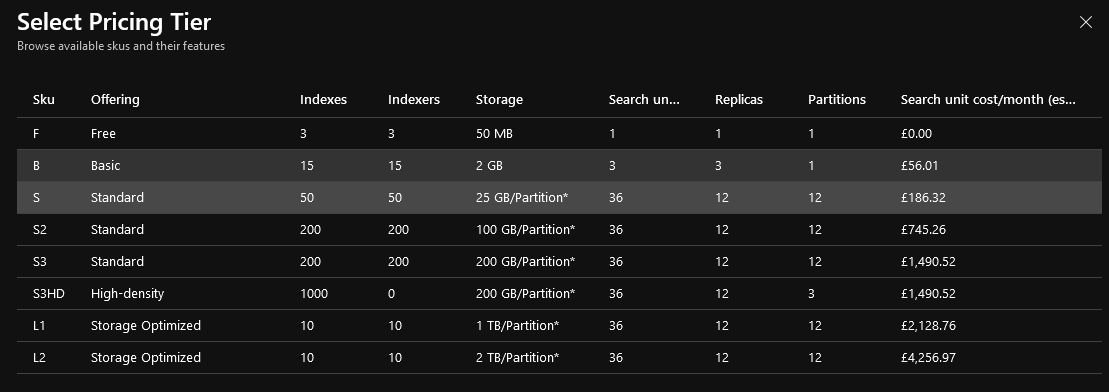
pricing tiers available as of today on the portal for Azure Cognitive Search.
Follow this video to see how to create a search service - https://www.youtube.com/watch?v=dMF5iGi8zag
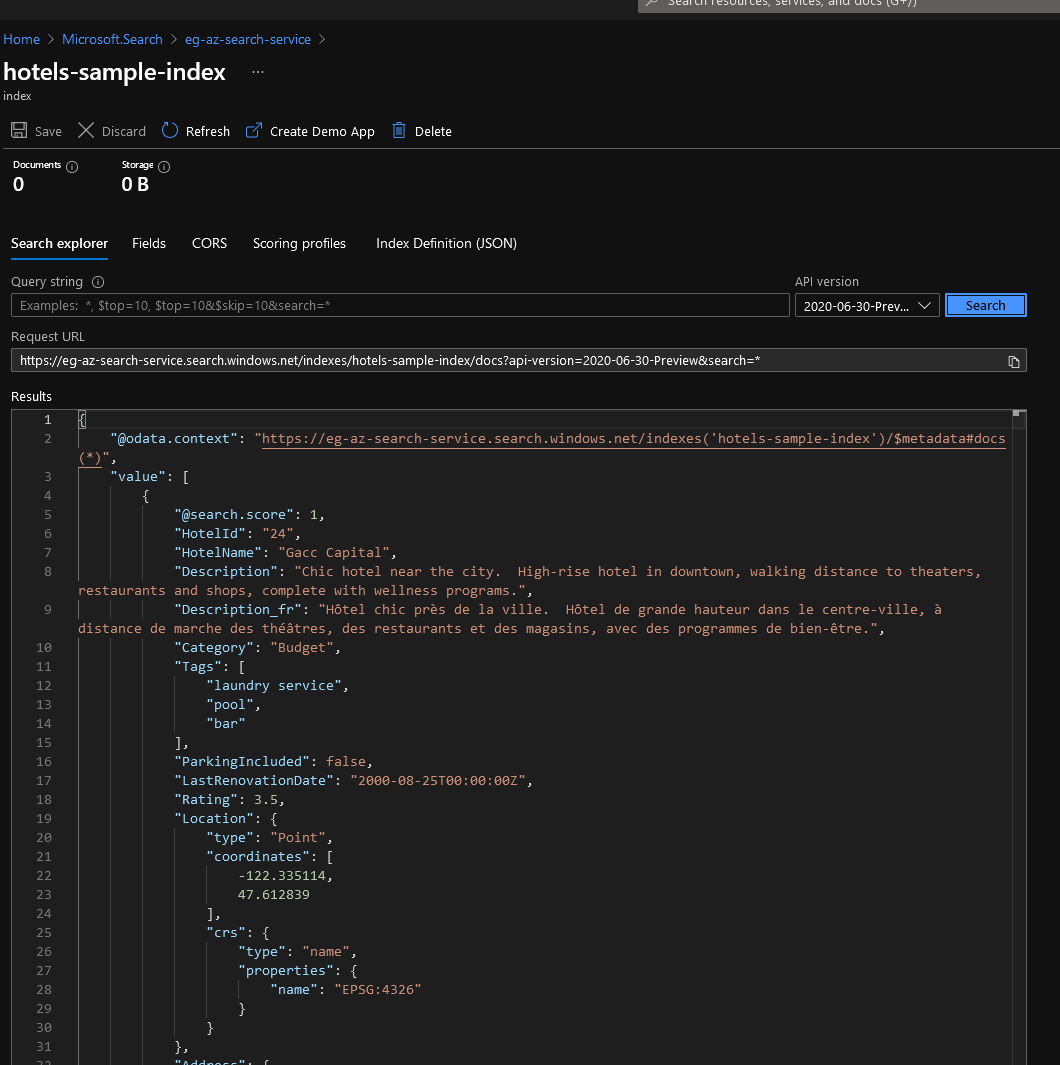
I just created an index for the sake of demonstrating it using the hotels sample datasource.
Next steps
Learn to query your data. I found that the docs are pretty good at explaining this, so I’m just going to point you there - https://docs.microsoft.com/en-us/azure/search/search-query-create
Azure also offers a semantic search feature, which sounds pretty exciting but I have not used it myself. So I might delve into that in another post. Apparently, it invokes a semantic ranking algorithm over a search result set and returns captions and semantic answers. This is currently under public preview.
References
- BillyTech’s quick intro to Azure Search - https://www.youtube.com/watch?v=Iodh0p1JJVY
- Indexers and supported data sources - https://docs.microsoft.com/en-us/azure/search/search-indexer-overview
- David Chappell and Associates - white paper on Azure Search -http://davidchappell.com/writing/white_papers/Introducing_Azure_Search-Chappell_v1.1.pdf