
Background
Imagine a server handling several 1000s of requests per second. There are so many coming in that suddenly the server has reached capacity. It cannot serve any more requests, it has to wait for existing resources to be freed first.
So how do we handle further requests? We could just make the server more powerful - install more CPU and RAM and things like that. But after a certain point the returns on this type of investments tends to go down to little. This type of scaling is called Scaling Vertically - as you are adding things to one server. However, there is another way, where you just add more servers to help deal with the increased number of incoming requests. This is called scaling horizontally. Let’s take a look at what allows you to scale horizontally.
Load Balancers
They balance the load of incoming client requests among the servers registered with it. So create a virtual pool of servers for the load balancers and it will ensure that incoming requests are directed to the one that’s most appropriate to serve at the time.
The load balancer is the entry point for all client requests, potentially behind a firewall somewhere. Also this sort of a setup may not be necessary if your server only expects a small amount of load. You don’t need a load balancer until there is a need to scale. Or maybe you do this for some sort of redundancy anyway.
What are the benefits of using one?
- Obviously allows you to scale your service, by adding multiple nodes/servers to the pool of available servers to the load balancer
- Secondly, it allows you to provide a highly available service. In case one of the servers in the pool is down, others can serve the requests. As the client doesn’t directly connect to the servers and only do this via the load balancer they end up getting a really seamless experience.
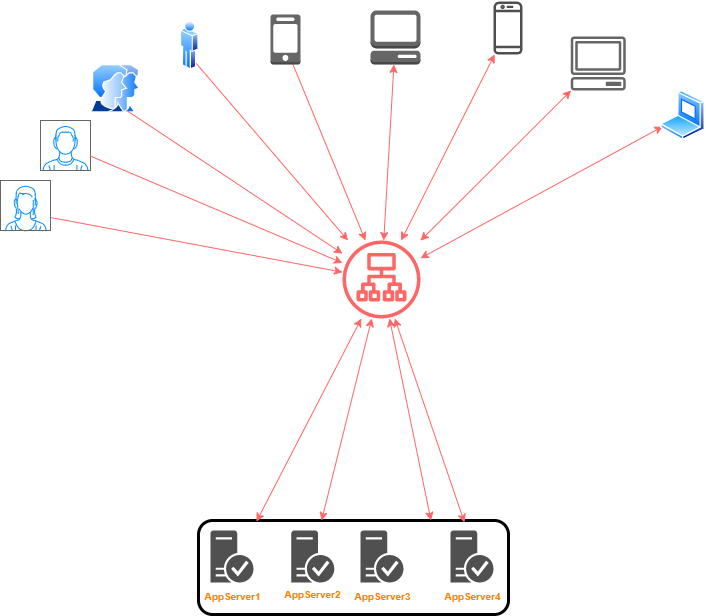
Where does it go in your architecture?
Most often you place a load balancer between a group of servers and clients because that’s where you are balancing the load.
Now your clients and servers can be of various types
- clients may be users of a web application and servers are the web and application servers making the web app possible
- clients maybe the application servers and servers maybe the database servers
What can load balancers do?
Load balancers do a lot of things. And you might you not have realised that it could do all these things.
- One of the most common things done by a load balancer is health monitoring of the servers. This is something made possible by the use of heartbeat protocol.
- Some load balancers help mitigate denial of service attacks
- Some load balancers can help with service discovery by performing service registry lookups
There may be more. But you are here to get better at system design interviews, not to get a PhD in load balancers.
What if the load balancer malfunctions?
Highly reliable and available systems are setup with at least a pair of load balancers. There are many ways that you can avoid your load balancer from becoming a single point of failure.
Deploying multiple load balancers behind a DNS based failover system or some other traffic distribution system could help reduce the likelihood of one load balancer becoming a single point of failure.
Global and Local load balancing
So far we have been talking about load balancers as if they all sit together in a room. We live in the era of cloud computing. So it is quite common to have things distributed geographically.
Global server load balancing
In simple terms, it is balancing the load between traffic across multiple geographic locations. Your favourite cloud provider does this behind the scenes, so does your favourite search engine and other popular websites. This is what makes failovers between regions possible. This is what makes it possible to create availability zones that keeps your applications available even when some of the regions could be suffering from outages!
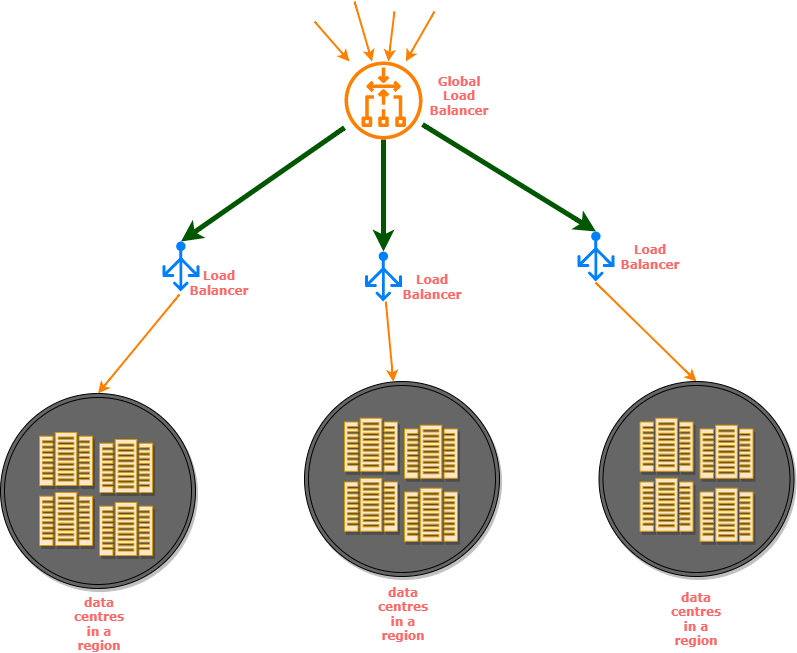
The regional load balancers provide the global load balancer with information regarding health of the servers in the corresponding data centres. It is a complex decision making process and these load balancers have multiple factors to consider to make the decision as when to failover, where to route incoming traffic, etc.
DNS and GSLB
The Domain name system does a bit of load balancing. DNS responds with a different list of IP address for every request. Thus it is probably not the most efficient load balancing but it is kind of spreading the load to a list of servers that it has. This reordering is sometimes called round-robin.
Local Load Balancers
These are a lot simpler compared to GSLB. These are generally located in the data-center. They are what most people use to define what a load balancer is, as it is easier to understand simpler concepts. Some times they are also called as a reverse proxy.
Common Load balancing algorithms
There are always going to be more than one way to achieve the same outcome. Thus there are different algorithms used in load balancing - broadly classified into static and dynamic based on how they distribute traffic.
Static algorithms
These algorithms are agnostic to the change in state of the server. This algorithm knows something about the servers in the pool but does not get up to date information on a regular basis. They are thus simpler and are usually what you find in a simple router.
Let’s explore some examples:
Round robin
Every request is forwarded to a server in the pool in a sequential manner, starting from the first one after the last has been served.
Weighted round robin
In scenarios where different servers in a server pool have different capacities or capabilities, then it makes sense to use a weighted round-robin. Each node is assigned a weight, sort of like an affinity factor. The heavier the weight assigned to a server, the more requests are sent to it.
IP Hashing
There might be situations where an application requires that several requests from the same user ends up with the same server in the pool due to the way the state of the application is conveyed. In this case, IP hashing technique could guarantee that the requests coming from the same IP would always go to the same server in the pool. I might have oversimplified the explanation here, but you get the idea (I hope).
URL Hashing
This is where your request URL determines which group of servers will serve your request. This might a clever way of balancing load when you know exactly which types of requests - all with a specific path in the URL, might need to be served by a very special set of servers. I will try and add examples here for reference.
Dynamic algorithms
These algorithms as you might have guessed from the definition of the static ones, is aware of some state information about the servers. It keeps this information up to date by regularly talking to the servers in the pool. Anything that involves this sort of state retention does add some complexity.
These algorithms require different load balancing servers to communicate with each other. They generally work like a small distributed system. The added complexity results in better decisions in picking the right place to forward the request. These algorithms ensure that the request is always forwarded to an active server in the pool and thus avoid any requests from ending up in a crashed server.
Examples are:
Least connections
If certain client requests can make applications on your server use a lot of processing or more resources in general, even with a small number requests to the same server, it could get overloaded. In these cases, the load balancer could maintain data about the number of connections to a server and make the choice of sending the client request to the server that has the least number of active connections. This ensures that the application continues to be responsive to the user even at times of heavy incoming traffic to the load balancer.
Least response time
When performance is a concern, you could also make your load balancer choose which server to send a request based on the most recent response times of the servers in the pool. This method also requires that the load balancers maintains some data on the response times of the servers in the pool.
State in Load Balancers
State in a load balancer is generally used to store session information for the clients interacting with the underlying web/application servers.
Not all session information is handled in the browser. Session information could be stored in a database or a distributed cache. Sometimes, some session information is also stored in the load balancers.
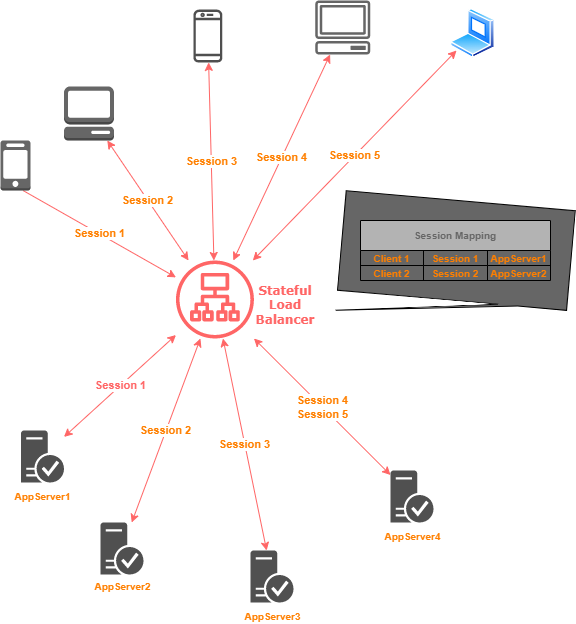
Stateful
In this technique of load balancing the state of the sessions between the client and server is maintained by the load balancer! Thus when balancing a request load it considers the state information and forwards requests accordingly.
It has a table like data structure that maps the client request to the hosting server. This is a complex setup and limits scalability because session information is distributed among load balancers. So decisions are made by coordination among a group of load balancers sharing state information.
A diagrammatic representation of a stateful load balancer in action.
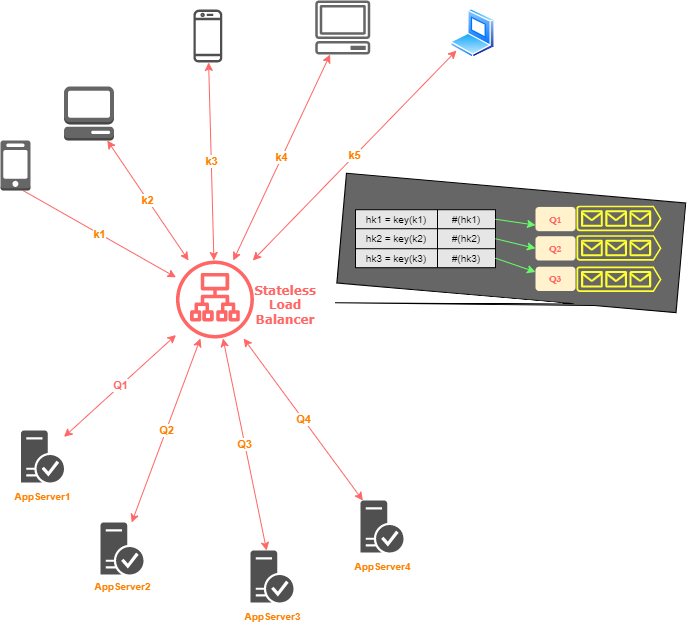
Stateless
As the name says - there is no state information in the load balancers involved! That’s one less responsibility, a huge one lesser than the stateful one! This means the load balancer’s algorithm to direct traffic can be a lot simpler. In most cases, an algorithm called consistent hashing is used to make forwarding decisions.
This might be a bit misleading as we will see why.
A stateless load balancer can struggle when the underlying infrastructure changes. Let’s say we suddenly get a couple of new servers in the application server pool!
Thus we might need some sort of state stored in each load balancer to maintain the list of application servers that the requests can be forwarded to. But this list isn’t shared across the load balancers. This is just maintained in the load balancer, keeping the state local and hence balancing decisions are made locally too.
The most common technique used by stateless load balancers is making a hash of the IP address of the client to a small number. This number is then used by the balancer to decide which server to forward the request to. You could also configure such a load balancer to use a round-robin algorithm by which the server picked could be entirely random. One client can create multiple requests to the server and hence hashing is often done on a combination of IP and port in order to ensure a good distribution. This is because clients generally create individual requests using a different port.
Summary
Let us take a look at the different types of load balancers and many other related concepts in the next one.
You could dive deeper into the topic of load balancing using Load Balancing TV by Avi Networks.