
Relational databases store data in a particular way and is therefore best suited for structured data. However, when your data isn’t very structured then it can be hard to optimise it for a relational database.
Why NoSQL?
Some of the commonly cited reasons for using a NoSQL database are:
- Simplicity: No structure, no impedance mismatch! Store anything, anyhow you want to. Easier to write applications for, less code or abstractions involved.
- Horizontal scalability: NoSQL databases were designed due to the limitations of traditional relational databases. Hence they are built to scale on distributed clusters, with increasing workloads on the database cluster could be handled by adding more commodity nodes to the cluster. NoSQL databases store data in documents that have all the information related to an entity in one doc rather than multiple tables that would have to be joined over several nodes. Thus in case of a node failure, the node can be evicted and the system will continue to perform.
- High Availability: Most NoSQL databases are built for high availability, to be deployed to a cluster of nodes that are a distributed system in itself. Nodes of a cluster can be taken off the pool and updated without any database downtime.
- Cost: most licenses for no-sql databases are available for commercial use without support for free. However, most RDBMS systems are expensive.
Now just because it has these advantages doesn’t mean you go and start an application design with a NoSQL database. Like any system design, start simple and scale when necessary.
Every distributed system is inherently complex. If you can solve the problem with less complexity, then do that. When it gets to the point where it is impossible to scale, then plan the switch.
Get it working. Then get it right.
Types of NoSQL databases
This is where things start to get interesting (as if it wasn’t already). Just like we have a new javascript framework every few months, there are so many types of NoSQL databases. The way you store data depends on how you want to retrieve it. That’s how we have different types of NoSQL databases.
Document database

Also known as a document oriented database is a database that is used to store and retrieve documents - not in google doc or word document format. This one stores data in XML, JSON, BSON.
There are some advantages to using a database like this one:
- Data-model that’s simple, fast and easy for developers to work with
- Flexible data schema that can evolve with the application
- Horizontally scalable
A document is a record that generally stores information about one object and any of its related metadata. Data is stored in field-value pairs. The values can be a variety of types and structures, including strings, numbers, dates, arrays or objects.
An example where document database can be used is when storing online profiles, which different users provide different types of information. Using a document database, you can store each user’s profile efficiently. Any changes to the profile and that document is replaced with a new version.
Example taken from MongoDB docs:
{
"_id": 1,
"first_name": "Tom",
"email": "tom@example.com",
"cell": "765-555-5555",
"likes": [
"fashion",
"spas",
"shopping"
],
"businesses": [
{
"name": "Entertainment 1080",
"partner": "Jean",
"status": "Bankrupt",
"date_founded": {
"$date": "2012-05-19T04:00:00Z"
}
},
{
"name": "Swag for Tweens",
"date_founded": {
"$date": "2012-11-01T04:00:00Z"
}
}
]
}Graph Database
As you might have already guessed, this one uses a Graph structure to store data. Nodes represent entities and edges show relationship between entities. The magic here is because of the way the node based organisation of relationships lead to interesting patterns analysing data becomes more fun. Some popular graph databases are: AWS Neptune, Neo4j, OrientDB.
Based on how Neo4j works, graph databases store nodes, relationships, labels and properties in separate files.
- Node: describes entities, or objects of a domain
- Labels: used to classify what kind of nodes they are - type of node
- Relationship: describes a connection between a source node and a target node. They are always directional and a type to say what type of relationship they are
- Properties: Nodes and relationships may have properties which are key-value pairs to describe them.
You can learn more on Neo4j’s GraphDB concepts online.
They have plenty of use-cases and one of them is to use them behind a recommendation engine.
Info
Example
Take the case of an e-commerce website where a customer bought a product and you could store the customer and product as nodes connected by the relationship bought and then recommend to that customer other products that other customers who bought a similar product had bought! I know, it is easier said than done, but graph databases make these type of queries easy.

Example graph from https://neo4j.com/docs/getting-started/appendix/graphdb-concepts/
Key-value database
Remember hash-tables in your data-structures class (if you took one)?
A hash-table is a data structure that maps keys to values.
A key-value database is just a bunch of key-value pairs. The keys are unique and values can be anything from simple integers to large complex objects.
A really good scenario where such a database can be used is for storing session information, mapping a session id to the object related to that session, storing everything about that session for easy retrieval and updates.
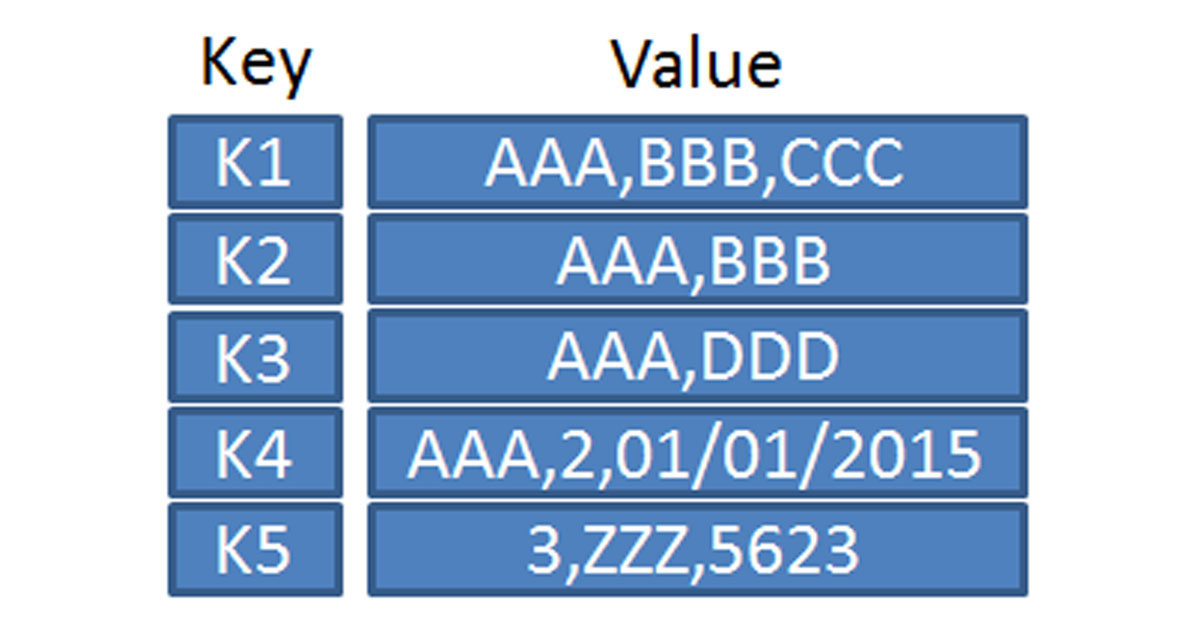
Some popular examples include Intersystems IRIS, Redis, Amazon DynamoDB, Apache Cassandra and the likes.
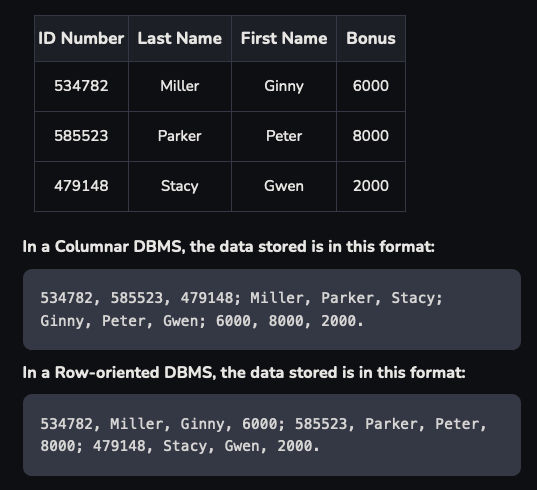
Columnar database
These databases are very different from traditional ones as they store data in columns instead of rows! They are particularly efficient at accessing data to all entries in a column. Some of most common popular columnar databases include Apache Cassandra, Snowflake, Amazon Redshift, HP Vertica, Google’s BigQuery!
These databases are excellent at performing analytics, large data aggregation queries. I have personally used Vertica for aggregating data spread over several years. As columnar databases read data from a column at once, there is just one seek and fetch - seek the date, fetch all data against it.
What’s the catch here? Disadvantages or shortcomings of NoSQL?
All relational databases conform to relational algebra.
“Relational algebra is the theory that uses algebraic structures with a well founded semantics for modelling data and defining queries on it. This theory was introduced by Edgar F Codd.” - Wikipedia on Relational algebra.
This conformance to a standard is exactly why you can write SQL to do the things you need from any relational database irrespective of the flavour - SQL Server, Oracle, etc.
That’s not true about NoSQL. Every NoSQL database does things its own way, even if it is of the same type. This lack of portability is a drawback.
Similarly, if you remember the CAP theorem, most NoSQL databases were designed for Availability and partition tolerance. Not Consistency. I wouldn’t say they won’t provide consistency, but most of them conform to Eventual Consistency. There are rarely support for data integrity like primary keys, foreign keys etc in a NoSQL database.
So how do I pick one?
Choose a relational database when …
- Data is structured
- ACID properties for transactions are important for your use-case
- If the data size is manageable without having to distribute it across a cluster
Choose a non-relational database when …
- Data is unstructured
- if the stored data has to be serialised and deserialized a lot
- if there is a huge amount of data, so large that it isn’t viable to store all that in a single node and expect good performance.