
Design a Content Delivery Network (CDN)
Complete CDN design walkthrough covering architecture, edge servers, caching policies, content propagation, cache invalidation, and serving content globally at scale.
Complete CDN design walkthrough covering architecture, edge servers, caching policies, content propagation, cache invalidation, and serving content globally at scale.
Complete key-value store design covering requirements, API design, consistent hashing, data partitioning, replication strategies, failure handling, and scaling.
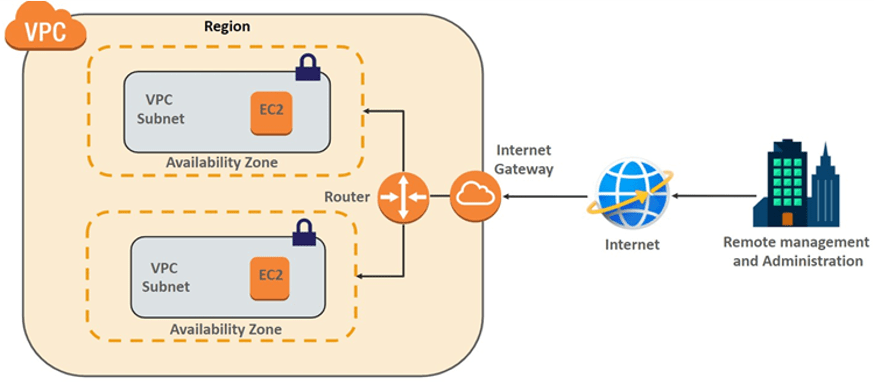
Do you ever feel like your network infrastructure is a black box? When I first dove into cloud networking, the term Virtual Private Cloud (VPC) sounded mysterious—like a secret compartment in the sky. Over the years, I’ve come to see a VPC as your custom sandbox inside a public cloud: a private playground built on shared real estate. In this post, we’ll unpack what a VPC really is, how it works under the hood, and why it’s an indispensable tool for any software craftsperson aiming for secure, scalable cloud architecture. ...
Complete guide to load balancer types covering Layer 4 (transport layer), Layer 7 (application layer), OSI model, and implementation strategies.
Complete guide to load balancers covering algorithms (round-robin, least connections), global vs local load balancing, stateful vs stateless approaches, and scaling strategies.
Complete guide to approximate calculations covering capacity estimation, bandwidth calculations, QPS estimation, storage planning, and latency numbers every engineer should know.
Complete guide to fault tolerance covering failure modes, redundancy strategies, circuit breakers, graceful degradation, and designing systems that survive failures.
Complete guide to system maintainability covering code quality, documentation, modularity, observability, and designing systems that evolve gracefully over time.
Complete guide to scalability covering horizontal and vertical scaling strategies, stateless architecture, caching, database sharding, and handling massive traffic.
Complete guide to system reliability covering MTBF (Mean Time Between Failures), MTTR (Mean Time To Recovery), fault tolerance, and building dependable distributed systems.